

Overview
ModernBERT-TR is a 150M-parameter encoder pretrained from scratch on 144.4 billion Turkish
tokens. The model uses the ModernBERT architecture: rotary position embeddings, gated linear units, alternating
local-global attention, and sequence-packed training.
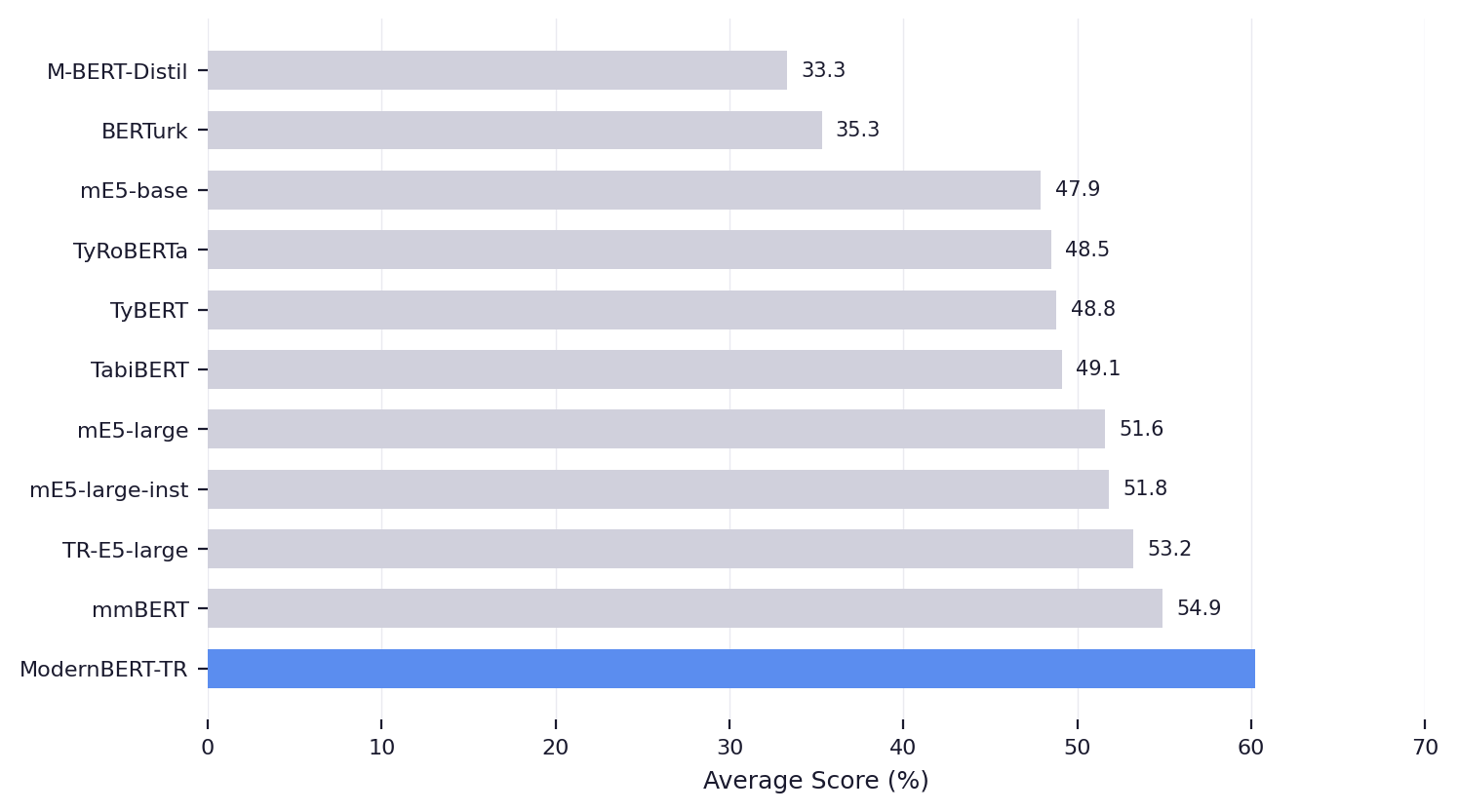
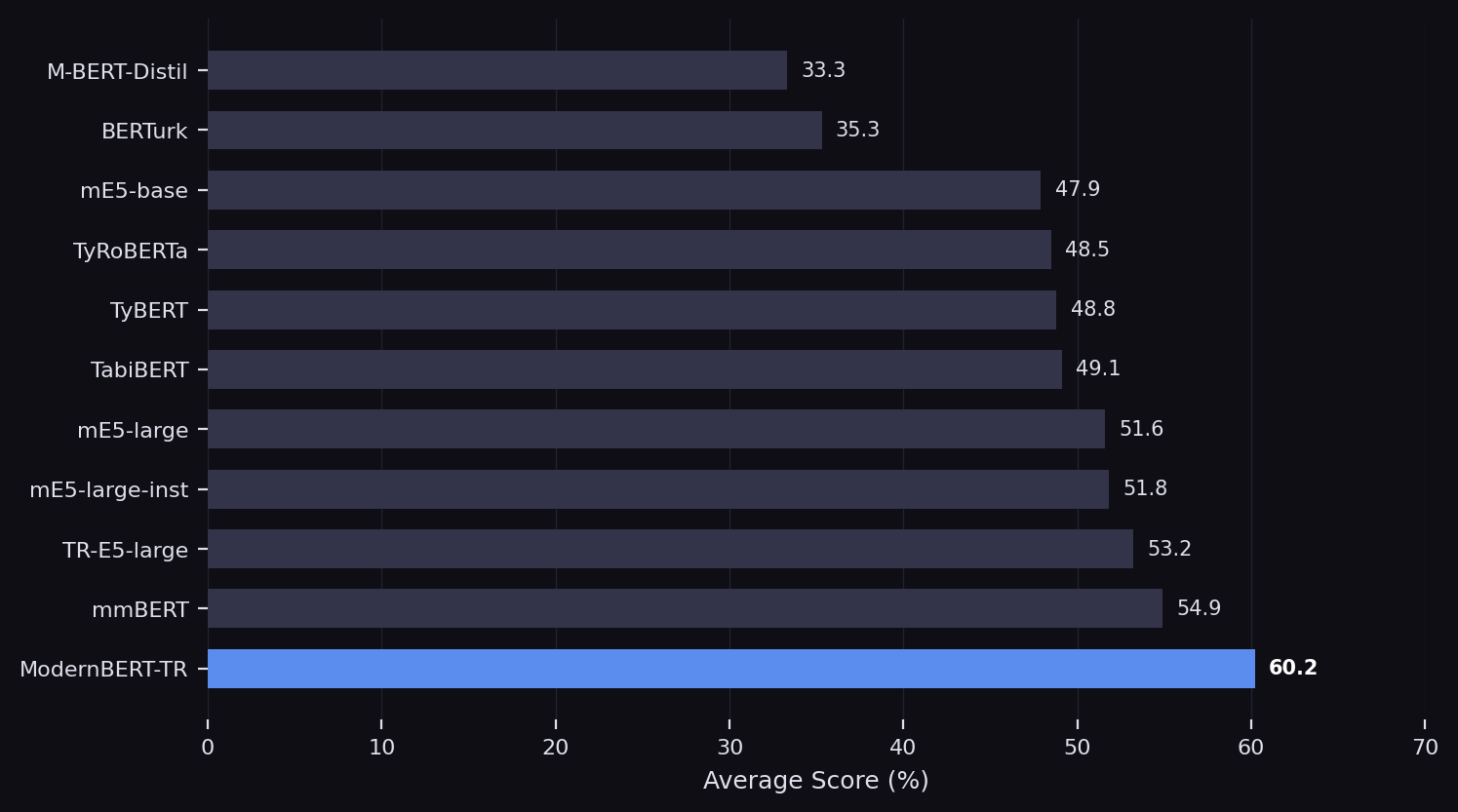
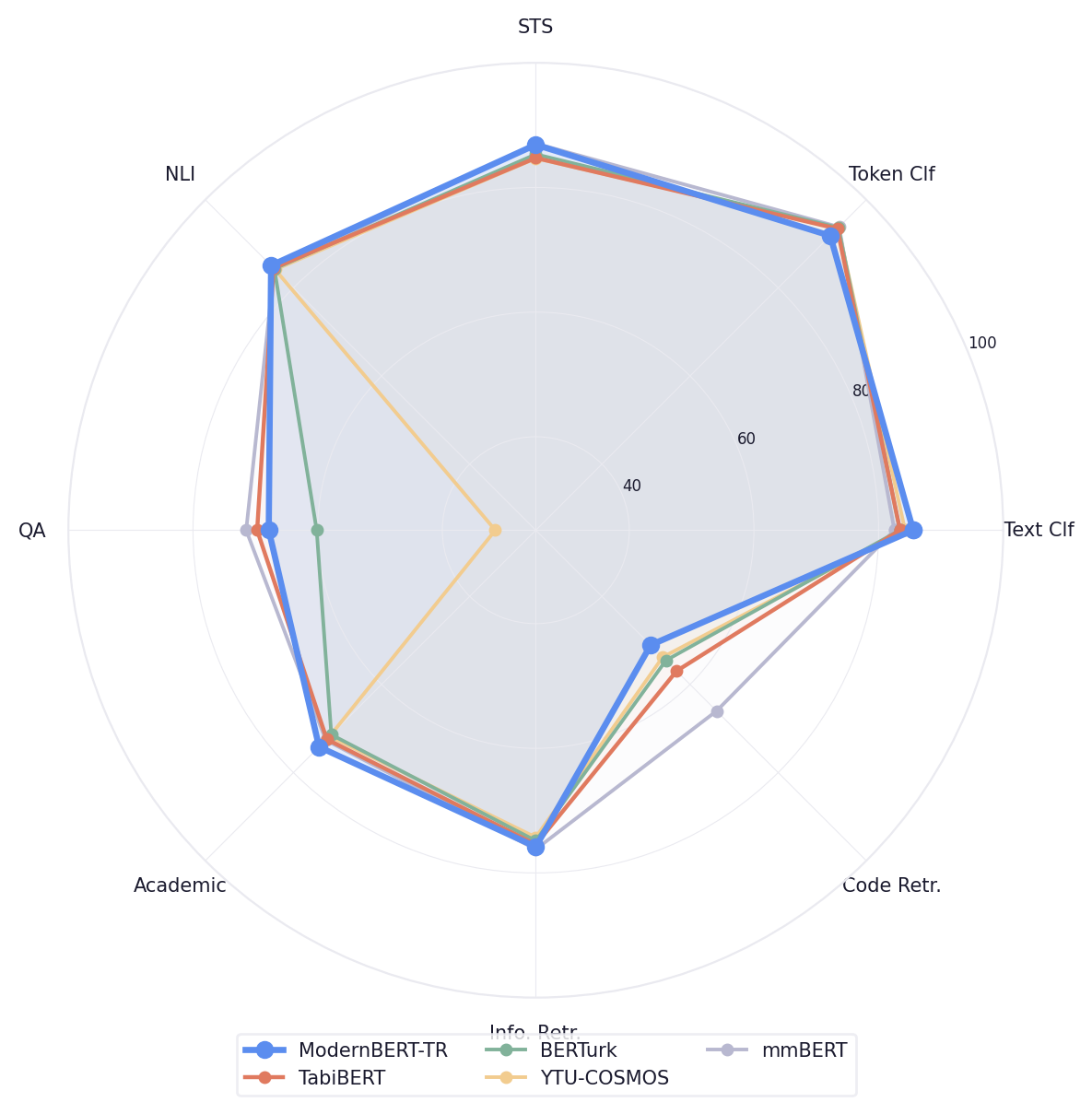
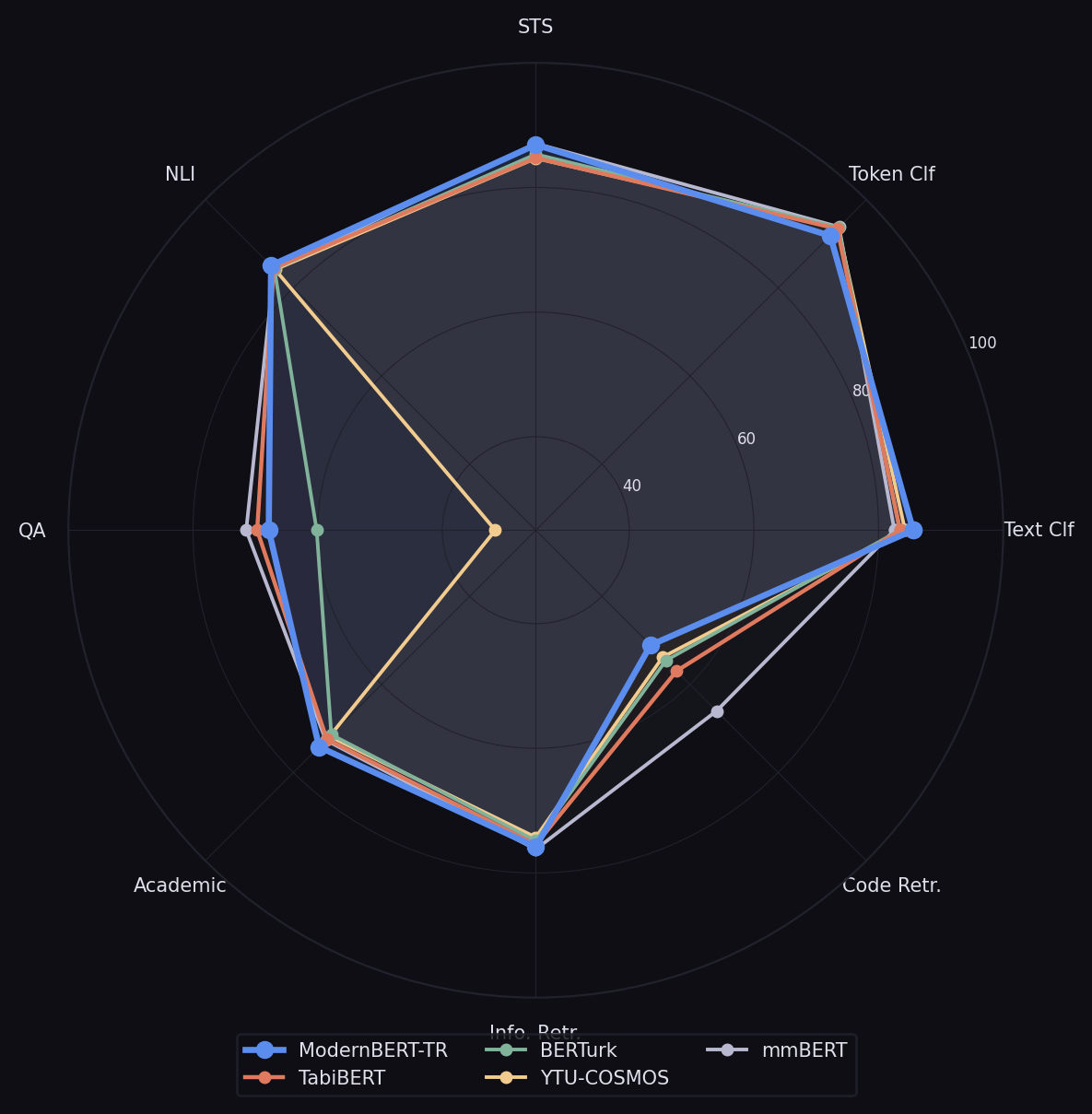
Under frozen-encoder linear probing, ModernBERT-TR achieves a 60.2% average across 11 Turkish NLP tasks,
surpassing the next-best model by 13.1% relative. Under full fine-tuning on the 28-task TabiBench benchmark, it
scores 77.28, matching TabiBERT within 0.30 points and leading in 5 of 8 categories despite training on 7x fewer
tokens.
Benchmark Results
Frozen-encoder linear probing across 11 Turkish NLP tasks spanning classification, regression, and token classification.
Per-Task Breakdown
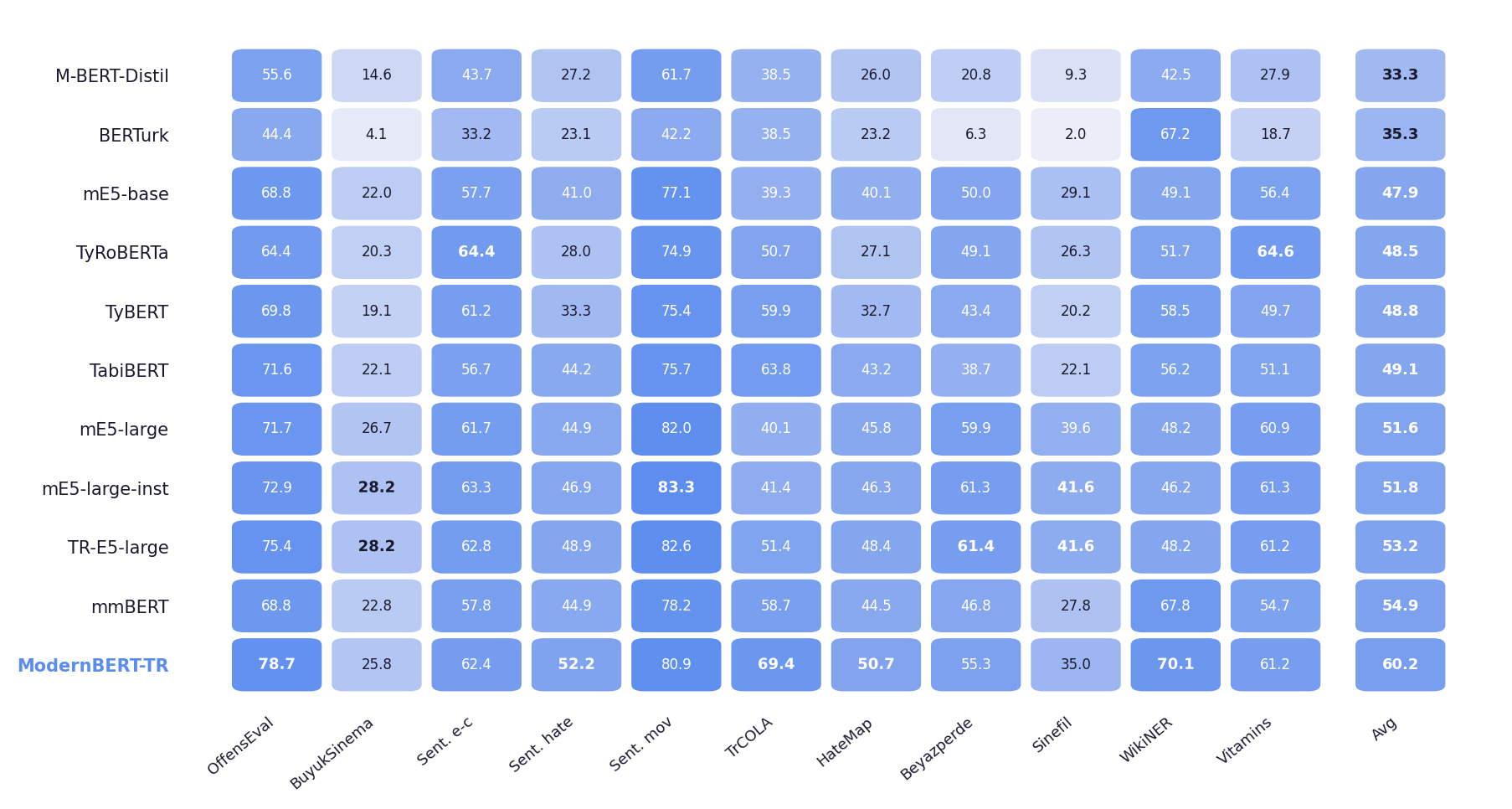
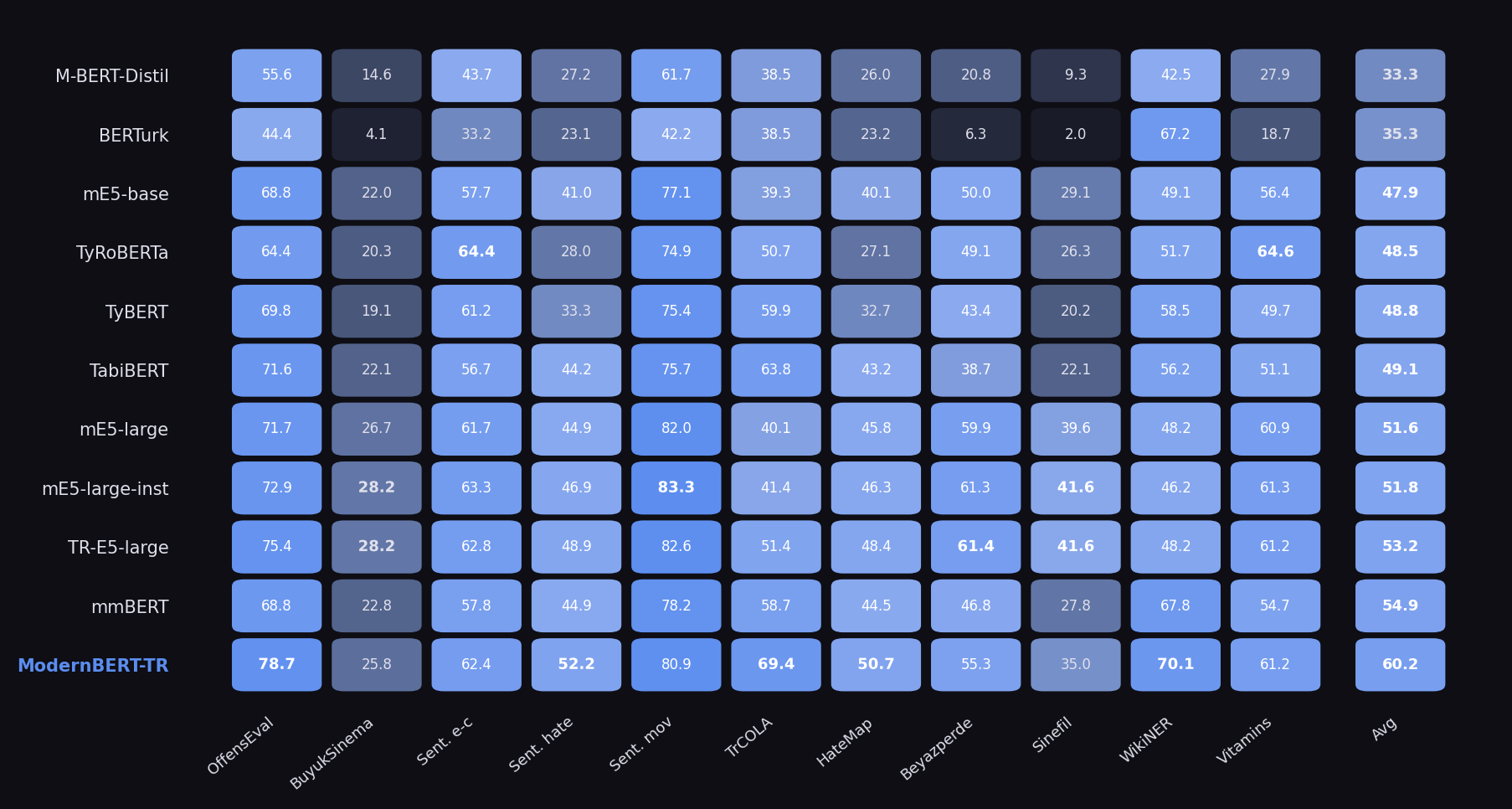
Best scores per task shown in bold. ModernBERT-TR leads on 5 of 11 tasks.
TabiBench Fine-Tuning
Full fine-tuning evaluation on the 28-task TabiBench benchmark with grid search over learning rate, weight decay, and batch size.
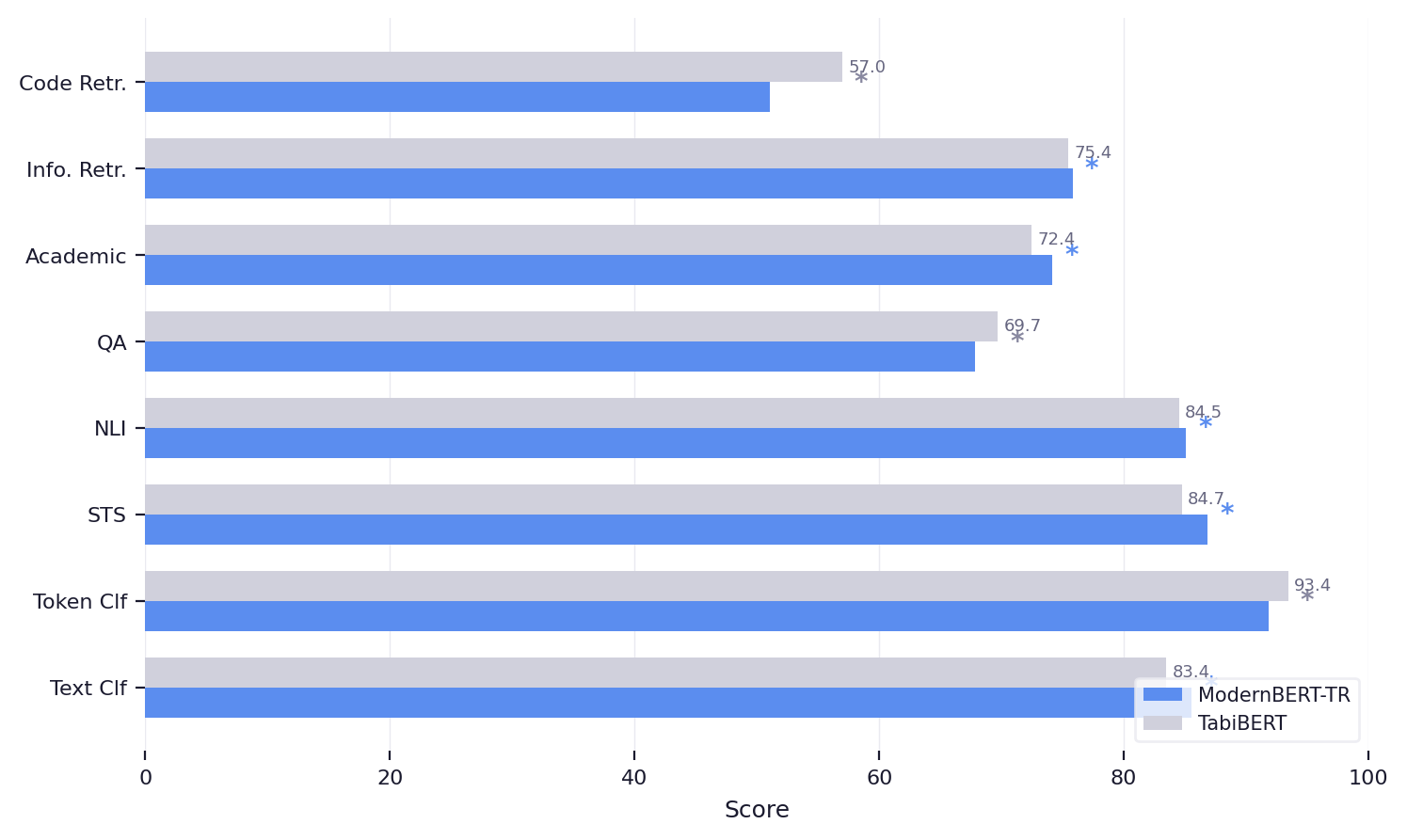
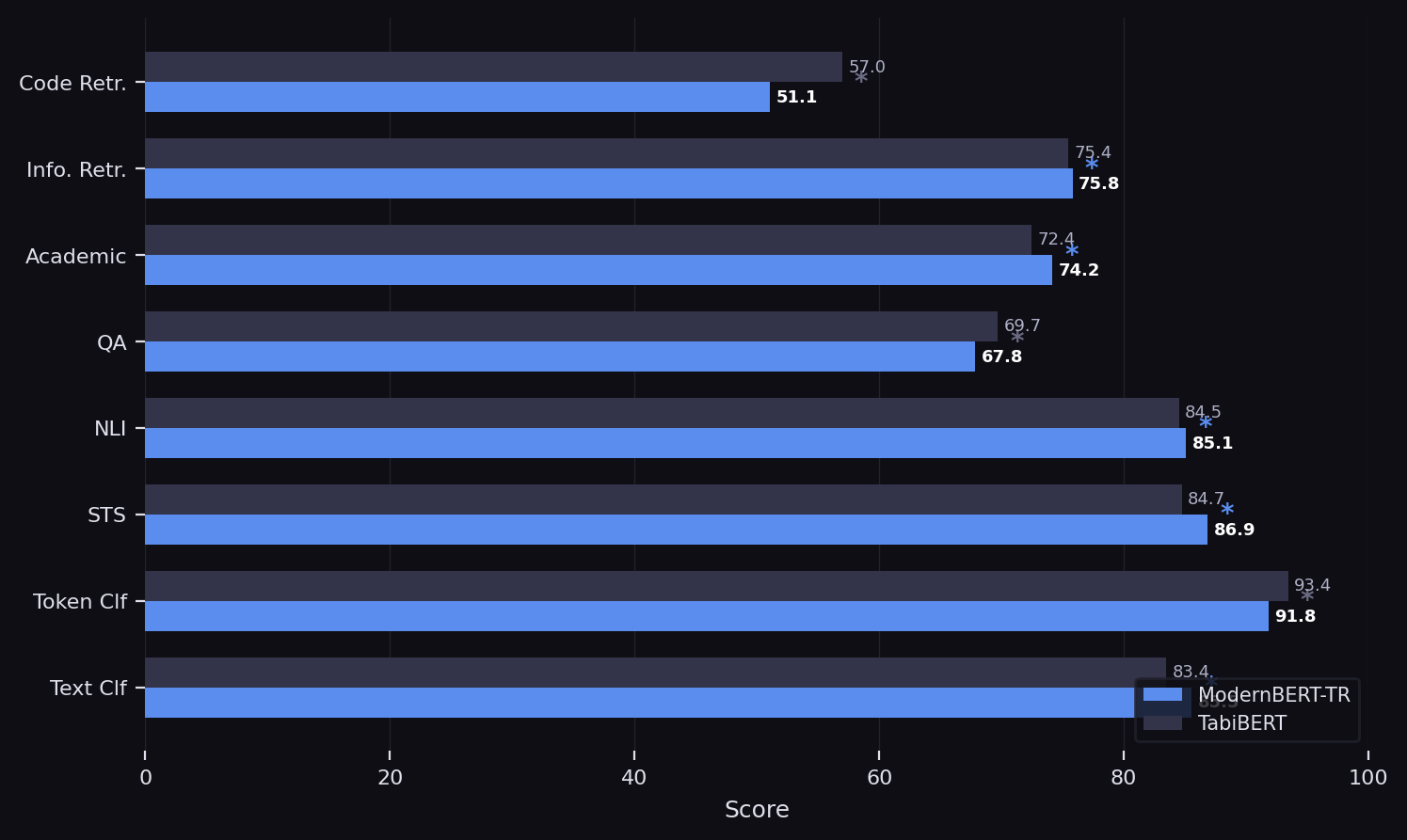
ModernBERT-TR (77.28) matches TabiBERT (77.58) and leads in 5 of 8 categories.
Training Data and Tokenizer
We combine FineWeb-2 Turkish (41.2B tokens) with BertTurk Corpus upsampled 5x (31.0B tokens), yielding 72.2B tokens per epoch trained for 2 full epochs. A custom 50K WordPiece tokenizer is trained on Turkish data, achieving strong compression with efficient vocabulary usage.
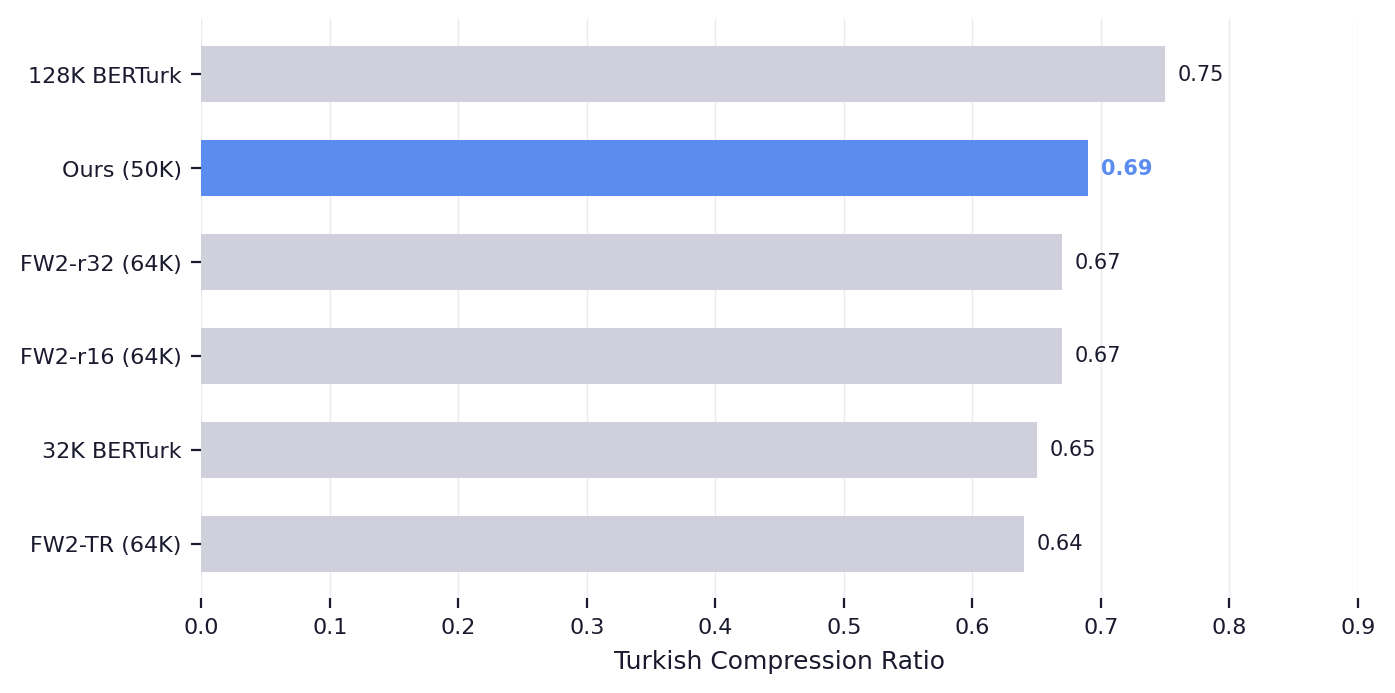
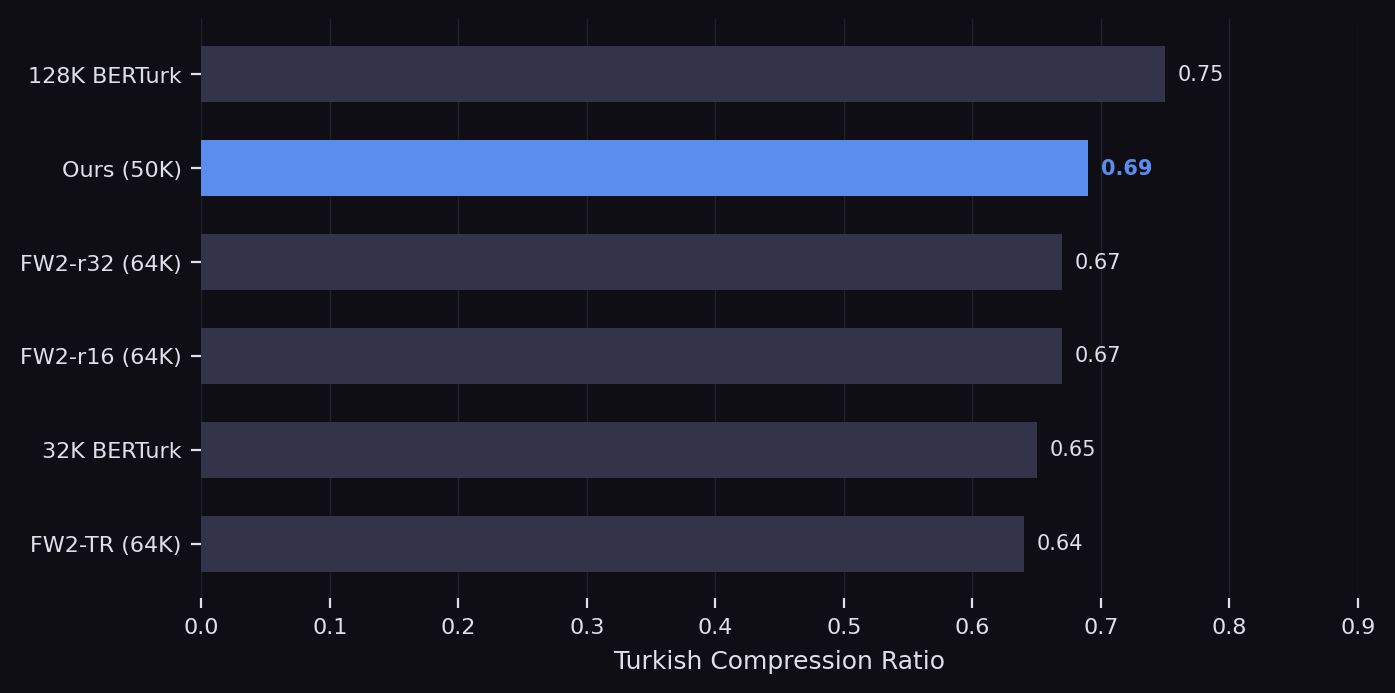
Turkish compression ratio across tokenizer configurations.
Methodology
ModernBERT-TR follows the ModernBERT-base architecture (22 layers, 768 hidden, 150M parameters) and was pretrained with systematic ablations to select the final configuration.
- Tokenizer Ablation Six configurations across vocabulary sizes (32K to 128K) and training corpora evaluated on compression efficiency.
- Hyperparameter Search Learning rate, batch size, schedule parameters, and data mixing ratios varied. Only LR and data mixture significantly affect quality.
- Data Curation Mixing ratio of BertTurk Corpus (5x upsampling) identified as a primary driver of downstream performance.
- Evaluation Protocol Frozen-encoder linear probing isolates representation quality from fine-tuning optimization choices.